
잡동사니 블로그
[논문 읽기] SAM 2: Segment Anything in Images and Videos 본문

1. Introduction
이미지에서는 segmentation이 잘 되었지만 이미지 수준을 넘어서는 segmentation이 필요함 즉 이미지를 넘어서는 비디오에서의 segmentation을 목표로 함.
지금까지의 비디오에서의 segmentation에서의 문제점
- 기존 엔티티들은 동작, 변형, 조명 변화와 같은 요인으로 인해 모양이 많이 바뀜.
- 비디오는 카메라 동작, 흐림 및 낮은 해상도로 인해 이미지보다 품질이 낮은 경우가 많음.
- 많은 수의 프레임을 효율적으로 처리하는 것.
그렇기 때문에 비디오 및 이미지 segmentation을 위한 통합 모델인 SAM2(Segment Anything Model 2)를 소개함 → 이미지를 단일 프레임 비디오로 간주 .
특히 이미지 segmentation을 비디오 영역으로 일반화 하기 위해 PVS(Promptable Visual Segmentation) 작업에 중점을 둠.
비디오의 모든 프레임에서 입력 포인트, 박스, 마스크를 사용하여 시공간 마스크인 masklet을 예측함 .
기존 모델들의 접근 방식과 비교했을 때, SAM2를 사용하는 것이 비슷한 품질에서 8.4배 빠르며, 모델의 학습에 사용된 최종 Segment Anything Video(SA-V) Data set은 50.9K 비디오에 걸쳐 35.5M 마스크로 구성되어 있으며, 기존의 모든 비디오 분할 데이터 세트보다 53배 더 많은 마스크로 구성됨.
Task: promptable visual segmentation
PVS 작업을 통해 비디오의 모든 프레임에서 모델에 프롬프트를 제공 할 수 있음. 프롬프트는 positive/negative 이거나 bounding box 이거나 mask일 수도 있음.
초기에 프롬프트를 수신하여 모델은 프롬프트를 전파하여 모든 비디오 프레임에서 얻을 수 있으며 비디오 전체에서 추가 프롬프트를 제공 할 수 있음.
frame 1에서 프롬프트를 제공하여 혀의 segment를 얻음. 녹색과 빨간색 점은 각각 positive, negative한 프롬프트를 나타냄.
SAM2가 객체를 잃은 경우 빨간색 화살표 처럼 추가 프롬프트 제공이 가능함.
Model
이 모델은 기존의 SAM을 동영상(및 이미지) 도메인에 일반화 시킴. SAM2는 비디오 전체 개별 프레임에서 Point box, Mask 프롬프트를 지원하여 Segment 하는 객체에 공간적 범위를 정의함.
마스크를 조정하기 위에 추가 프롬프트 입력이 가능하며 프레임에 메모리는 현재 예측을 기반으로 memory encoder에서 생성 되어서 후속 프레임에서 사용할 수 있도록 memory bank에 정리됨.
그리하여 이미지 인코더에서 프레임당 imbedding을 가져와 memory bank에서 이전 프레임에 사용하였던 조건을 부여하여 임베딩을 생성한 후 다음 mask decoder로 전달.
→ 그렇기 때문에 기존 SAM에서는 이미지만 가능하였지만 SAM2는 비디오도 가능
Image encoder
긴 비디오를 실시간으로 처리하기 위해 스트리밍 방식을 사용 가능해지면 사용. Image encoder는 전체 상호작용에 대하여 한번만 되며(즉 프레임마다 반복적으로 새로 feature 추출을 하지 않음) feature embeddings를 제공 하는 역할을 함.
Memory attention
이전 프레임에서의 feature와 새로운 프롬프트를 바탕으로 현재 프레임의 feature, 를 조정하는 역할.
Prompt encoder & mask decoder
프롬프트는 (positive | negative ) 포인트, 바운딩 박스, 마스크로 프롬프트하여 주어진 프레임에서 객체의 범위를 정의할 수 있음. 프롬프트는 positional encoding과 각 프롬프트에 따라 학습된 embedding의 합으로 표현되며, 마스크는 합성곱을 사용하여 frame embedding과 합산됨.
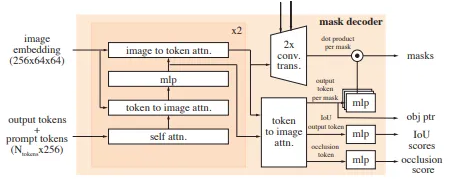
SAM과 비슷하게 bidirectional transformer블록을 쌓아 frame embedding프레임 임베딩을 업데이트하며, 모호한 프롬프트는 여러 마스크를 예측함 . 후속 프롬프트가 모호성을 해결하지 못하면, 모델은 현재 프레임에 대해 예측된 IoU가 가장 높은 마스크만 전파함.
Memory encoder : convolutional module를 사용하여 출력 마스크를 다운 샘플링 함.
https://github.com/facebookresearch/sam2
GitHub - facebookresearch/sam2: The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2
The repository provides code for running inference with the Meta Segment Anything Model 2 (SAM 2), links for downloading the trained model checkpoints, and example notebooks that show how to use th...
github.com
더 간단하게 테스트 해볼려면
Meta Segment Anything Model 2
Access our research Open innovation To enable the research community to build upon this work, we’re publicly releasing a pretrained Segment Anything 2 model, along with the SA-V dataset, a demo, and code. Download the model Highlights We are providing tr
ai.meta.com
'공부용' 카테고리의 다른 글
| 현재 디렉토리에서 하위 디렉토리까지 ipynb_checkpoints 지우기 (0) | 2025.02.05 |
|---|---|
| Gradient Accumulation (0) | 2025.01.01 |
| Kmedoids clustering (3) | 2024.10.16 |
| Dice Coefficient(Dice Score) -> Dice Loss Function (1) | 2024.10.09 |
| [LG Aimers] Module 2. Mathematics for ML - Matrix Decomposition (1) | 2024.01.06 |


