
잡동사니 블로그
Kmedoids clustering 본문
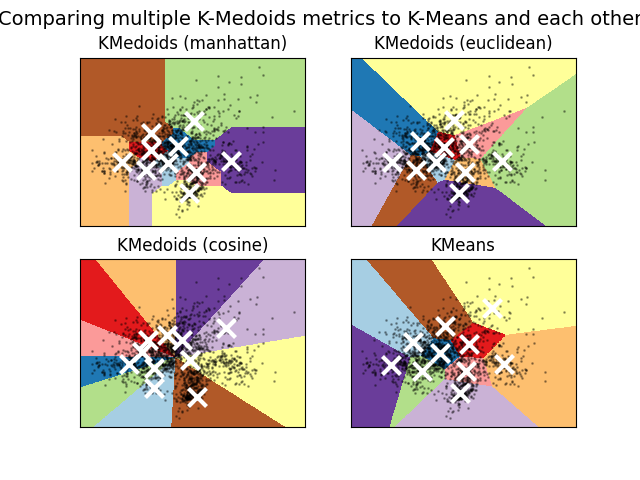
K-medoids의 목표는 각 데이터 포인트가 가장 가까운 대표점(medoids)에 할당되었을 때, 그 거리를 최소화하는 것이며, 일반적으로는 유클리드 거리(Euclidean distance)기반 그 합을 최소화 하는것이 목표.(Cosine similarity도 가능)
- K-means: 군집의 중심을 각 군집에 속한 데이터 포인트의 평균(mean)으로 정의함. 즉, 군집의 중심은 데이터 공간의 임의의 점이 됨.
- K-medoids: 군집의 중심을 데이터 포인트 중 하나로 선택 되기 때문에 그 중심은 반드시 실제로 존재하는 데이터이며, 이를 통해 K-medoids는 K-means보다 이상치(outlier)에 덜 민감해짐.
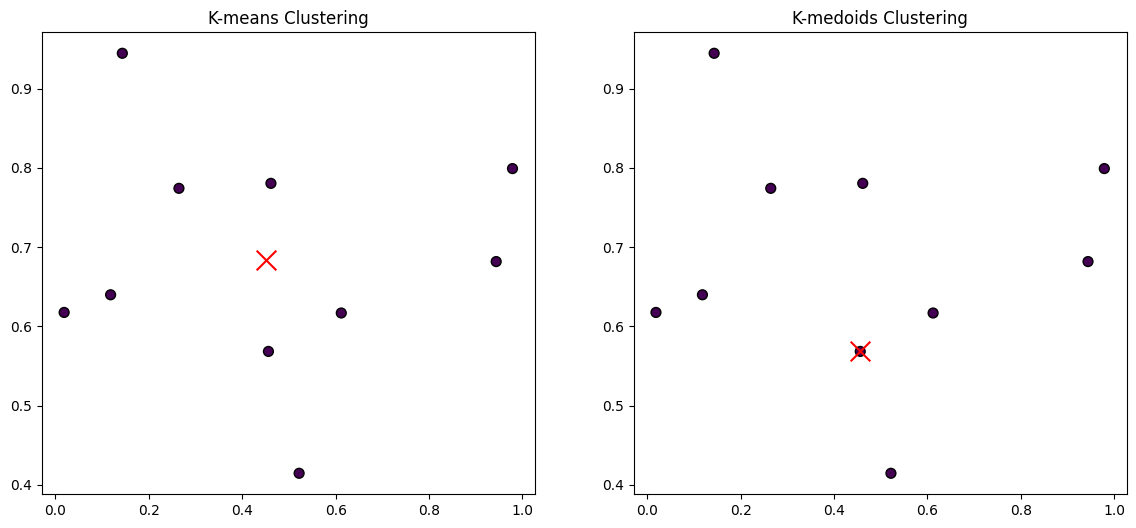
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn_extra.cluster import KMedoids
X = np.random.rand(10, 2)
# K-means
kmeans = KMeans(n_clusters=1, random_state=0)
kmeans_labels = kmeans.fit_predict(X)
# K-medoids
kmedoids = KMedoids(n_clusters=1, random_state=0)
kmedoids_labels = kmedoids.fit_predict(X)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
ax1.scatter(X[:, 0], X[:, 1], c=kmeans_labels, cmap='viridis', marker='o', edgecolor='k', s=50)
ax1.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='red', marker='x')
ax1.set_title('K-means Clustering')
ax2.scatter(X[:, 0], X[:, 1], c=kmedoids_labels, cmap='viridis', marker='o', edgecolor='k', s=50)
ax2.scatter(X[kmedoids.medoid_indices_, 0], X[kmedoids.medoid_indices_, 1], s=200, c='red', marker='x')
ax2.set_title('K-medoids Clustering')
plt.show()
'공부용' 카테고리의 다른 글
| Gradient Accumulation (0) | 2025.01.01 |
|---|---|
| [논문 읽기] SAM 2: Segment Anything in Images and Videos (3) | 2024.10.29 |
| Dice Coefficient(Dice Score) -> Dice Loss Function (1) | 2024.10.09 |
| [LG Aimers] Module 2. Mathematics for ML - Matrix Decomposition (1) | 2024.01.06 |
| [논문 읽기] TabTransformer: Tabular Data Modeling Using Contextual Embeddings (0) | 2023.11.16 |
'공부용' Related Articles
more



