
잡동사니 블로그
[Kaggle] 신용카드 사기 분류(Credit Card Fraud Detection) 본문
파이썬 입문한지 약 3달째 연습데이터로 하기 좋은 Kaggle에 신용카드 사기 분류 데이터로 연습해보았다.
데이터셋 다운로드는 아래 링크로.
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
from sklearn.metrics import confusion_matrix, f1_score, roc_auc_score
from imblearn.over_sampling import SVMSMOTE
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
from sklearn.ensemble import RandomForestClassifier
df = pd.read_csv('creditcard.csv', encoding='cp949', sep=',', thousands = ',')
Data Information
Class에 대해 분류를 해야하기 때문에 Class의 분포를 본다.
sns.countplot(x="Class", data=df)
plt.title("Class_value_counts")
plt.show()
df['Class'].value_counts()
#0 284315
#1 492
#Name: Class, dtype: int640은 정상 1은 사기인데 비율이 월등히 작다.
print(df.info())
df.isna().sum()
## Column Non-Null Count Dtype
#--- ------ -------------- -----
# 0 Time 284807 non-null float64
# 1 V1 284807 non-null float64
# 2 V2 284807 non-null float64
# 3 V3 284807 non-null float64
# 4 V4 284807 non-null float64
# 5 V5 284807 non-null float64
# 6 V6 284807 non-null float64
# 7 V7 284807 non-null float64
# 8 V8 284807 non-null float64
# 9 V9 284807 non-null float64
# 10 V10 284807 non-null float64
# 11 V11 284807 non-null float64
# 12 V12 284807 non-null float64
# 13 V13 284807 non-null float64
# 14 V14 284807 non-null float64
# 15 V15 284807 non-null float64
# 16 V16 284807 non-null float64
# 17 V17 284807 non-null float64
# 18 V18 284807 non-null float64
# 19 V19 284807 non-null float64
# 20 V20 284807 non-null float64
# 21 V21 284807 non-null float64
# 22 V22 284807 non-null float64
# 23 V23 284807 non-null float64
# 24 V24 284807 non-null float64
# 25 V25 284807 non-null float64
# 26 V26 284807 non-null float64
# 27 V27 284807 non-null float64
# 28 V28 284807 non-null float64
# 29 Amount 284807 non-null float64
# 30 Class 284807 non-null int64
#dtypes: float64(30), int64(1)
#memory usage: 67.4 MB
#None
#Time 0
#V1 0
#V2 0
#V3 0
#V4 0
#V5 0
#V6 0
#V7 0
#V8 0
#V9 0
#V10 0
#V11 0
#V12 0
#V13 0
#V14 0
#V15 0
#V16 0
#V17 0
#V18 0
#V19 0
#V20 0
#V21 0
#V22 0
#V23 0
#V24 0
#V25 0
#V26 0
#V27 0
#V28 0
#Amount 0
#Class 0
#dtype: int64각 feature들은 float형이고 결측치도 없는것을 보아 매우 깔끔한 데이터로 예상해본다.
coulmns들은 V1~V28의 의미는 알 수 없고 Amount는 사용 금액인데 Time은 잘 모르겠다...
Boxplot
plt.figure(figsize = (15, 15))
p = 1
try:
for i in df:
if p <= len(df):
plt.subplot(6, 5, p)
sns.boxplot( x = 'Class', y = df[i], palette="Set3", data = df)
p += 1
except :
print("")
plt.tight_layout()
plt.show()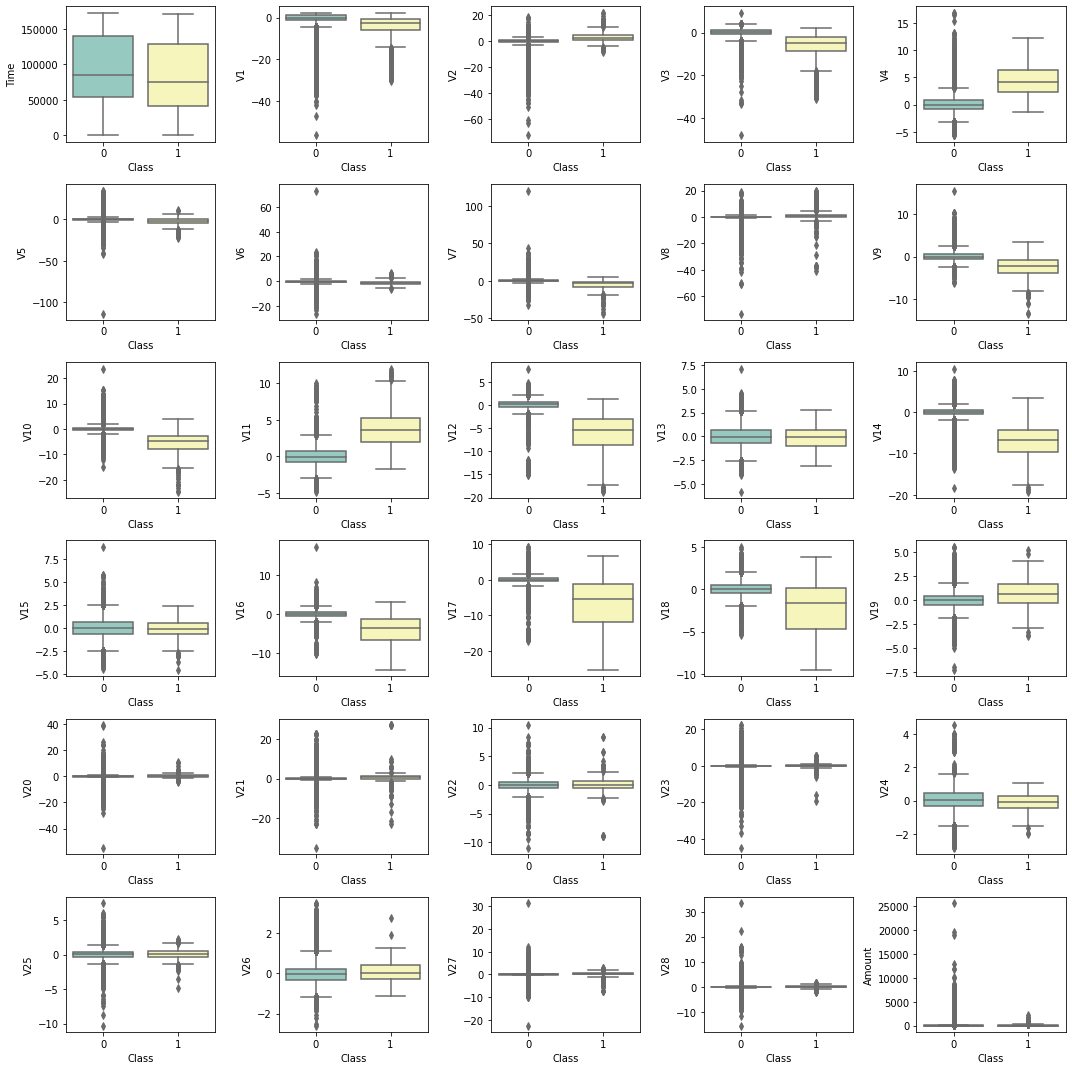
이상치가 제법 많다.
Feature Select
# 범위를 부여해서 그래프를 그리는 함수
def plot_histo(df, title, col_no, bins) :
# i+1번째 열 이름 선택
col_name=df.columns[col_no]
#정상
df_yes=df[(df['Class']==0)]
X_yes =df_yes.loc[:,col_name].values
#불량
df_no=df[(df['Class']==1)]
X_no = df_no.loc[:,col_name].values
plt.style.use('seaborn')
plt.subplot(6,5,col_no+1)
plt.hist(X_yes, color = 'blue', alpha = 0.3, bins = bins, label = '0', density = True,)
plt.hist(X_no, color = 'red', alpha = 0.4, bins = bins, label = '1', density = True)
plt.gca().spines['right'].set_visible(False) #오른쪽 테두리 제거
plt.gca().spines['top'].set_visible(False) #위 테두리 제거
plt.xticks(fontsize=8)
plt.yticks(fontsize=8)
plt.title(title, size = 10)
plt.legend(fontsize = 8
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize = (30, 30))
for i in range(0,30):
plot_histo(df,df.columns[i],i,60)
plt.show()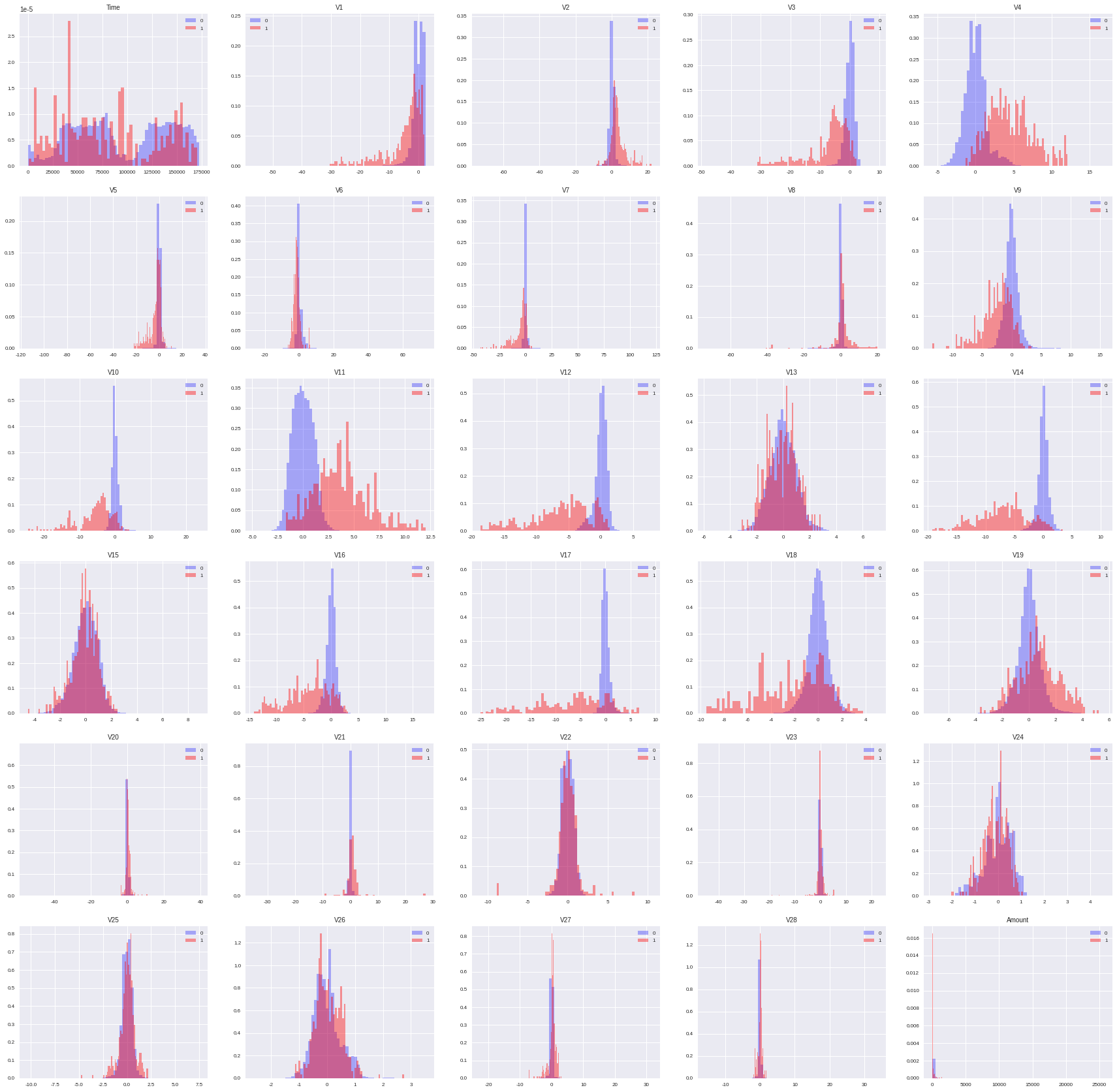
안중요해보이는 변수들은 본인 판단하에 삭제하고 Train과 Test로 분리 하였다.
X_data = df.iloc[:,:-1]
X_data.drop(labels=['V6','V13','V15','V20','V21','V22','V23','V24','V25','V26','V28'],axis=1,inplace=True)
y_data = df.iloc[:,-1:]
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=128, stratify = y_data)
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
#(227845, 19) (56962, 19)
#(227845, 1) (56962, 1)Modeling
이상치에 강한 RobustScaler를 이용해 스케일링 해주고,
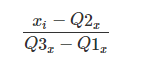
다양한 오버샘플링이 있어서 나는 그동안 써보며 괜찮았던 SVM(support vector machine)을 이용한 SMOTE 오버 샘플링을 사용 하였다.
https://eupppo.tistory.com/entry/SMOTE-Over-sampling%EC%98%A4%EB%B2%84%EC%83%98%ED%94%8C%EB%A7%81
SMOTE를 활용한 Over sampling(오버샘플링)
내가 처음으로 기업의 데이터로 프로젝트를 하며 정상과 불량의 데이터 수 차이가 나는 불균형 데이터(imbalanced data)였기에 이 때 쓰는 방법인 오버샘플링(Over sampling)을 쓰며... 주로 분류(classifica
eupppo.tistory.com
robust=RobustScaler().fit(X_train)
X_train = robust.transform(X_train)
X_test = robust.transform(X_test)
svm = SVMSMOTE(random_state=1, n_jobs=-1)
X_train, y_train = svm.fit_resample(X_train,y_train)대표적인 앙상블(ensemble) 모델인 Random Forest를 이용하여 모델링 해보았다.
RFC = RandomForestClassifier(
n_estimators = 6
)
evals = [(X_test, y_test)]
RFC.fit(X_train, y_train)
pred = RFC.predict(X_test)
pred_proba = RFC.predict_proba(X_test)
pred_th = [ 1 if x > 0.5 else 0 for x in pred_proba[:,1]]
get_clf_eval(y_test,pred_th)
print('train_score :',RFC.score(X_train,y_train),'test_score :',RFC.score(X_test,y_test))
#/오차행렬:
# [[56852 12]
# [ 16 82]]
#정확도: 0.9995
#정밀도: 0.8723
#재현율: 0.8367
#F1: 0.8542
#AUC: 0.9183
#train_score : 0.9999560344865488 test_score : 0.9995084442259752Features importance
warnings.simplefilter(action='ignore', category=FutureWarning)
feature_imp = pd.DataFrame(sorted(zip(lgbm_wrapper.feature_importances_,X_data.columns[:])), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False))
plt.title('Features')
plt.tight_layout()
plt.show()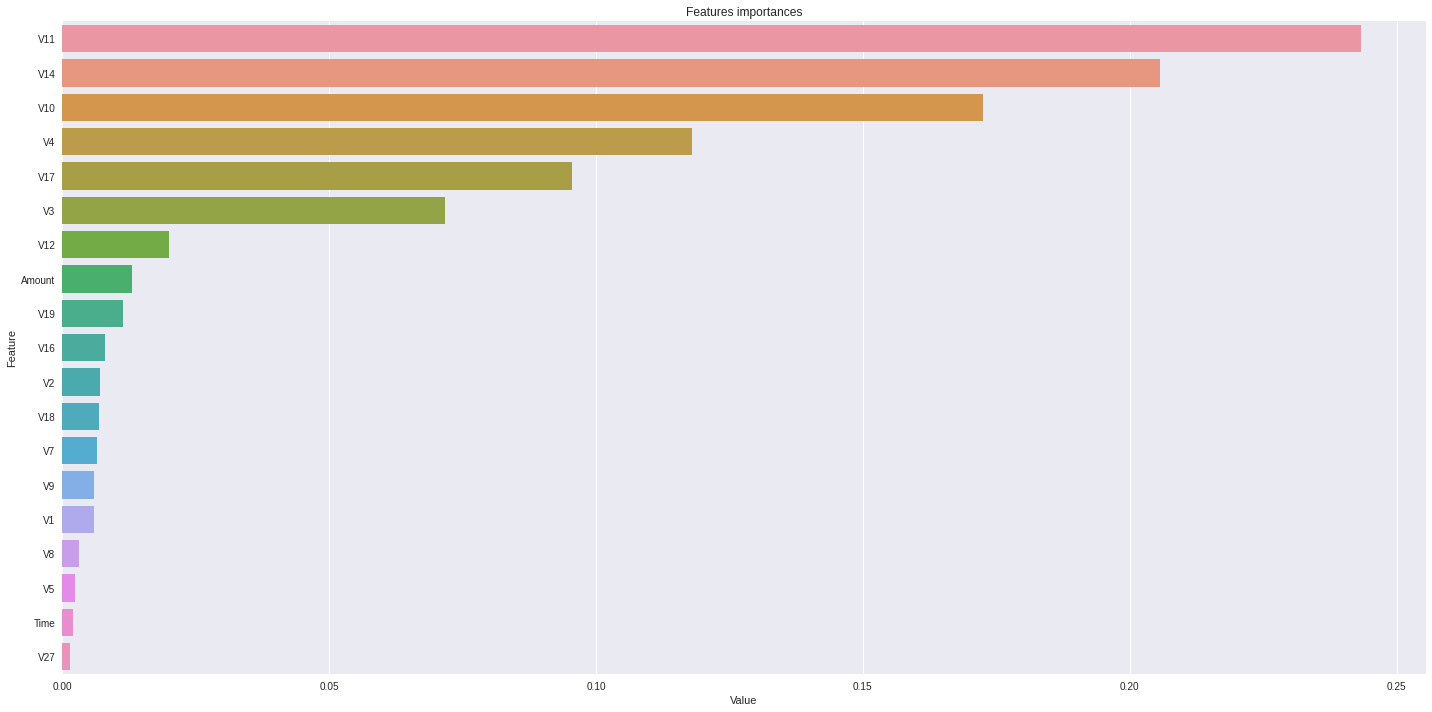
결론 :
변수 선택 때 V27과 시간 빼는걸 고민 했었는데 역시 중요도가 낮게 나온다.
암 환자 발견과, 신용 카드 사기 같은 모델은 재현율(Recoll)이 중요한데 이상치 제거와 파라미터 조정등을 거친다면 조금은 더 올릴 수 있지 않을까?
데이터 셋이 좋아서 결과가 잘 나왔지 안그랬으면 안나왔을 F1 Score일듯.
경험을 더 쌓아야겠다는 생각이 든다.
틀린점이나 수정할점 있으면 댓글로 부탁드려요!
참조 :
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.RobustScaler.html
'Python' 카테고리의 다른 글
| [Python] pytorch와 sklearn의 train_test_split 활용하여 데이터 셋 나누기와 간단한 CNN (0) | 2023.09.07 |
|---|---|
| [Python] Selenium과 bs4를 이용한 크롤링 + Pyautogui (0) | 2023.08.28 |
| [Python] 시각화에 주로 쓰이는 라이브러리 3가지 (0) | 2023.08.26 |
| T-SNE 차원 축소 시각화 (0) | 2022.09.08 |
| SMOTE를 활용한 Over sampling(오버샘플링) (5) | 2022.09.01 |



