
잡동사니 블로그
[Python] Selenium과 bs4를 이용한 크롤링 + Pyautogui 본문
크롤링 기본 구조
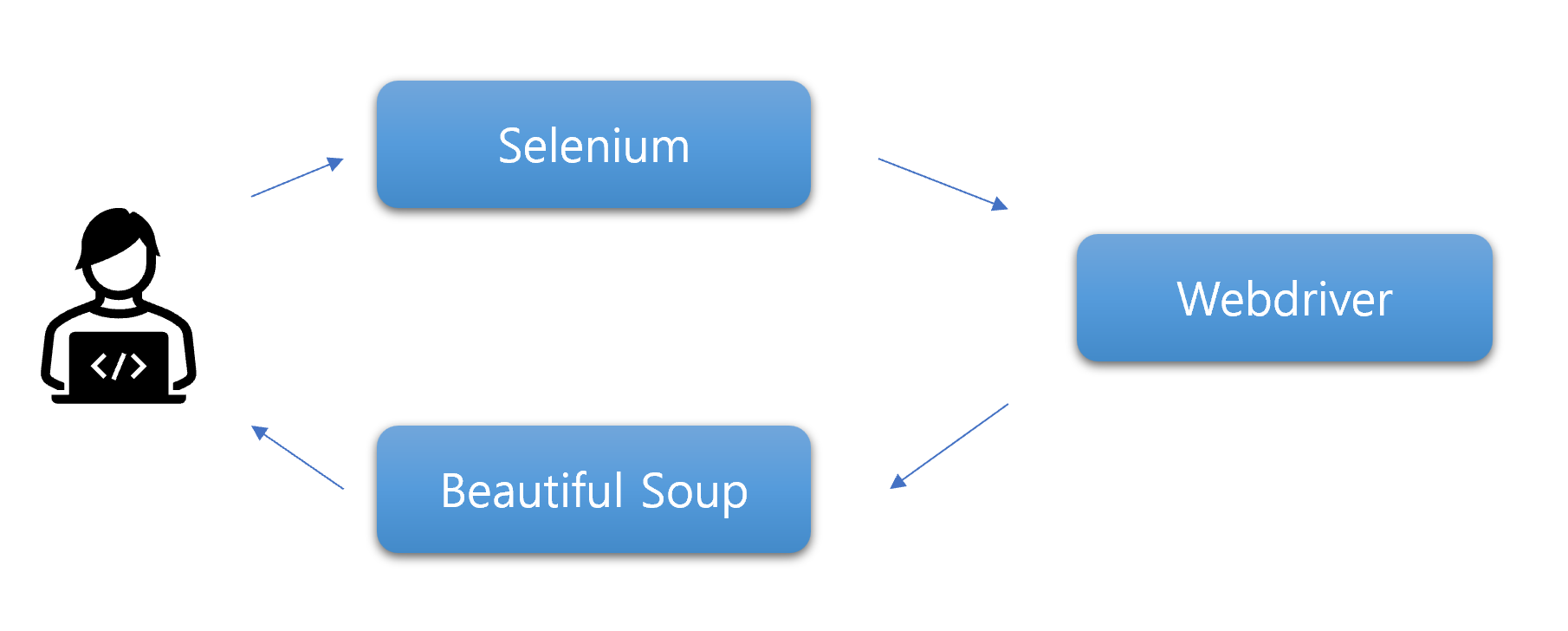
1. Selenium을 사용하여 소스코드로 지정된 WebDriver를 실행하여 웹 페이지에 접속한다.
2. 접속한 웹 페이지를 HTML 소스코드 형태로 파싱한다.
3. 파싱된 HTML 전체 코드에서 Beautiful Soup를 사용하여 원하는 부분만 골라낸다.
4. 골라낸 데이터를 원하는 형식의 파일로 저장한다.
크롬 버전확인 및 드라이버 설정

https://googlechromelabs.github.io/chrome-for-testing/
Chrome for Testing availability
chrome-headless-shellmac-arm64https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/118.0.5951.0/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
chromedriver.chromium.org
114이전 까지는 밑에 링크에서 다운 받을 수 있었는데 어느샌가 안올라와서 위 링크에서 다운 받음.
pip install beautifulsoup4pip install seleniumhttps://www.koreabaseball.com/Schedule/Schedule.aspx
KBO 홈페이지
KBO, 한국야구위원회, 프로야구, KBO 리그, 퓨처스리그, 프로야구순위, 프로야구 일정
www.koreabaseball.com

내가 가져올 정보들은 우클릭 검사나 위와 같은 버튼을 눌러서 위치를 찾고 copy xpath나 element를 이용
나는 각팀의 스코어 보드를 크롤링하기 위해

div에 tbl-type06이라는 테이블에 모든 행(tr)을 가져와서 원하는 형식으로 바꿔서 csv로 저장함.
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'https://www.koreabaseball.com/Schedule/Schedule.aspx'
driver.get(url)
time.sleep(2)
html_1 = driver.page_source
soup_1 = BeautifulSoup(html_1, 'html.parser')
q=soup_1.find('div','tbl-type06').find_all('tr')
total = []
for i in q[1:]:
game = i.find('td', 'play').get_text()
time = i.find('td', 'time').get_text()
p = game.split('vs')
team1 = p[0]
team2 = p[1]
try:
day = i.find('td', 'day').get_text()
except:
day=day
team1_name = ''.join([c for c in team1 if not c.isdigit()])
team1_score = ''.join([c for c in team1 if c.isdigit()])
team2_name = ''.join([c for c in team2 if not c.isdigit()])
team2_score = ''.join([c for c in team2 if c.isdigit()])
total.append((day,time,team1_name, team1_score, team2_name, team2_score))
df = pd.DataFrame(total, columns=['날짜','시간','팀1', '점수1', '팀2', '점수2'])
df.to_csv('new.csv', encoding='utf-8-sig', index=False)
Pyautogui
추가로 pyautogui 라이브러리를 통해 마우스 및 키보드를 제어하여 동적 사이트 크롤링도 가능하다.
예전에 리뷰 감성분석을 진행하며 네이버 리뷰 크롤링 할 유용하게 썼었다.

구글맵에선 리뷰가 스크롤을 내려야 나오는 형태이기에 pyautogui.scroll을 사용하여 스크롤 내리기 사용하였음.
아래는 잠시 만들어본 코드이며, 크롤링을 제대로 할려면 반복문 조건 수정등이 필요.
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import pyautogui
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
url = 'https://www.google.co.kr/maps/place/%EB%8F%84%EA%B9%A8%EB%B9%84%EC%8A%A4%EC%8B%9C/data=!4m6!3m5!1s0x357c9e494ebd86a9:0x933773b066cbd9eb!8m2!3d37.4957052!4d126.9048033!16s%2Fg%2F11f3n5v1f4?hl=ko&entry=ttu'
driver.get(url)
time.sleep(3)
element=driver.find_element(By.XPATH, '//*[@id="QA0Szd"]/div/div/div[1]/div[2]/div/div[1]/div/div/div[3]/div/div/button[2]')
element.click()
driver.maximize_window()
click_x = 357
click_y = 971
num_scrolls = 5
pyautogui.click()
for _ in range(num_scrolls):
pyautogui.moveTo(click_x, click_y, duration=0.5)
pyautogui.scroll(-4000)
time.sleep(1)
html_1 = driver.page_source
soup_1 = BeautifulSoup(html_1, 'html.parser')
span_elements = soup_1.find_all("span", class_="wiI7pd")
nick_elements = soup_1.find_all("div", class_="d4r55")
for span, nick in zip(span_elements, nick_elements):
print(nick.get_text())
print(span.get_text())
print("-"*30)
'Python' 카테고리의 다른 글
| [Python] OpenCV로 Contour 및 Color 검출 하기 (0) | 2023.09.13 |
|---|---|
| [Python] pytorch와 sklearn의 train_test_split 활용하여 데이터 셋 나누기와 간단한 CNN (0) | 2023.09.07 |
| [Python] 시각화에 주로 쓰이는 라이브러리 3가지 (0) | 2023.08.26 |
| T-SNE 차원 축소 시각화 (0) | 2022.09.08 |
| [Kaggle] 신용카드 사기 분류(Credit Card Fraud Detection) (1) | 2022.09.02 |



