
잡동사니 블로그
[Python] Multi-input model in pytorch 본문
AI Model을 설계할 때 가끔 Input이 여러개를 원할 경우가 있다. 예를들면 Image와 Categorical featurer가 동시에 들어간다면 좋을텐데 라는 생각도 들어서
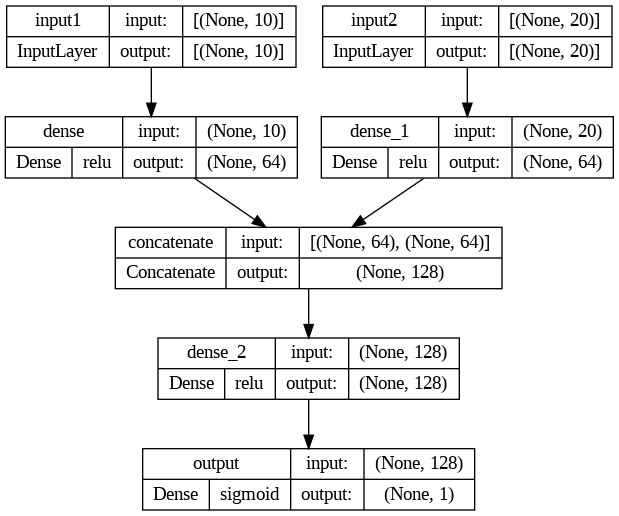
Pytorch에서는 이를 해결 하기 위해 아래와 같은 코드가 사용됨.
torch.cat((out1, out2), dim=1)
from sklearn.datasets import load_iris
import torch
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
from sklearn.metrics import f1_score
class Dataset(Dataset):
def __init__(self, X_1, X_2, y):
self.X_1 = X_1
self.X_2 = X_2
self.y = y
def __len__(self):
return len(self.X_1)
def __getitem__(self, idx):
return torch.FloatTensor(self.X_1[idx]), torch.FloatTensor(self.X_2[idx]), torch.LongTensor([self.y[idx]])
class MyDataLoader:
def __init__(self, X1, X2, y, batch_size=32, shuffle=True):
self.dataset = Dataset(X1, X2, y)
self.batch_size = batch_size
self.shuffle = shuffle
self.dataloader = DataLoader(self.dataset, batch_size=batch_size, shuffle=shuffle)
def __iter__(self):
return iter(self.dataloader)
def __len__(self):
return len(self.dataloader)
class Multiinput(nn.Module):
def __init__(self, input_size1, input_size2, hidden_size, num_classes):
super(Multiinput, self).__init__()
self.fc1 = nn.Linear(input_size1, hidden_size)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(input_size2, hidden_size)
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(hidden_size * 2, num_classes*2)
self.relu3 = nn.ReLU()
self.fc4 = nn.Linear(num_classes*2,num_classes)
def forward(self, input1, input2):
out1 = self.relu1(self.fc1(input1))
out2 = self.relu2(self.fc2(input2))
combined = torch.cat((out1, out2), dim=1)
out3 = self.relu3(self.fc3(combined))
out = self.fc4(out3)
return out
#데이터셋 불러오기
iris = load_iris()
X = iris.data
y = iris.target
#분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#X_1 = 꽃받침(sepal), X_2 = 꽃잎(petal)
X1_train, X1_test = X_train[:, :2], X_test[:, :2]
X2_train, X2_test = X_train[:, 2:], X_test[:, 2:]
train_dataloader = MyDataLoader(X1_train, X2_train, y_train, batch_size=32, shuffle=True)
test_dataloader = MyDataLoader(X1_test, X2_test, y_test, batch_size=32, shuffle=False)
# 모델 초기화 및 손실 함수, 최적화 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=Multiinput(input_size1=2, input_size2=2, hidden_size=8, num_classes=3).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 훈련
num_epochs = 100
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs1, inputs2, labels in train_dataloader:
inputs1, inputs2, labels = inputs1.to(device), inputs2.to(device), labels.to(device)
labels = labels.squeeze()
optimizer.zero_grad()
outputs = model(inputs1, inputs2)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {running_loss / len(train_dataloader)}")
#모델 평가
model.eval()
predictions = []
with torch.no_grad():
for inputs1, inputs2, labels in test_dataloader:
inputs1, inputs2, labels = inputs1.to(device), inputs2.to(device), labels.to(device)
outputs = model(inputs1, inputs2)
probabilities = F.softmax(outputs, dim=1)
_, predicted = torch.max(probabilities, 1)
predictions.extend(predicted.numpy())
predictions = np.array(predictions)
print(f1_score(y_test, predictions, average='micro'))
#Epoch 100/100, Training Loss: 0.3295845165848732
#1.0
'Python' 카테고리의 다른 글
| [Python] Class imbalance -> Class weight (0) | 2024.02.19 |
|---|---|
| [Python] Multi-label & Multi-class classification에서의 loss function in pytorch (0) | 2023.12.03 |
| [Python] 심심해서 만든 무신사 추천상품 크롤링 (1) | 2023.11.20 |
| [Python] TabTransformer to use Tensorflow (0) | 2023.11.19 |
| [Python] Folium을 이용한 지도 시각화 (1) | 2023.10.24 |
'Python' Related Articles
more



